





Quelles solutions techniques pour améliorer la performance de votre site web ?
change de nom...
Largement utilisée par les sociétés d'hébergement pour le monitoring des serveurs et services web, l'utilisation d'Elastic Stack (Elastichsearch, Logstah, Kibana) sur des données métiers est plus confidentielle. Dans cet article, nous testons et vous partageons notre retour sur la dernière version disponible de la stack, la 7.10, dans ce contexte.
L’objectif est d'explorer et de mettre en œuvre un tableau de bord de suivi d'activité. Aucune analyse et conception d'entrepôt de données préalable ne seront réalisées. L'objectif est de tirer pleinement parti de la puissance d’indexation d’Elasticsearch,
Nous apporterons une attention particulière sur les points suivants :
“Elasticsearch est un moteur de recherche et d'analyse RESTful distribué et conçu pour répondre à une multitude de cas d'utilisation. Et leur liste ne cesse de s'enrichir. Véritable clé de voûte de la Suite Elastic, il centralise le stockage de vos données et vous permet d'élargir le champ des possibles. Vos données n'ont plus aucun secret pour vous.”
“Logstash est un pipeline open source côté serveur, destiné au traitement des données. Sa mission ? Ingérer simultanément des données provenant d'une multitude de sources, puis les transformer et les envoyer vers votre système de stockage préféré. (Bon, nous, bien sûr, on préfère Elasticsearch.)”
“Kibana vous permet de visualiser vos données Elasticsearch et de naviguer dans la Suite Elastic. Vous voulez comprendre pourquoi on vous appelle à 2 h du matin ou évaluer l'impact de la pluie sur votre chiffre d'affaires trimestriel ? Kibana vous permet de le faire.”
En interne, nous utilisons l’application Redmine pour effectuer la gestion de nos projets. Les principales fonctionnalité de cet outil sont :
Une API Http Rest est disponible pour manipuler les données de cet ERP :
http://www.redmine.org/projects/redmine/wiki/Rest_api
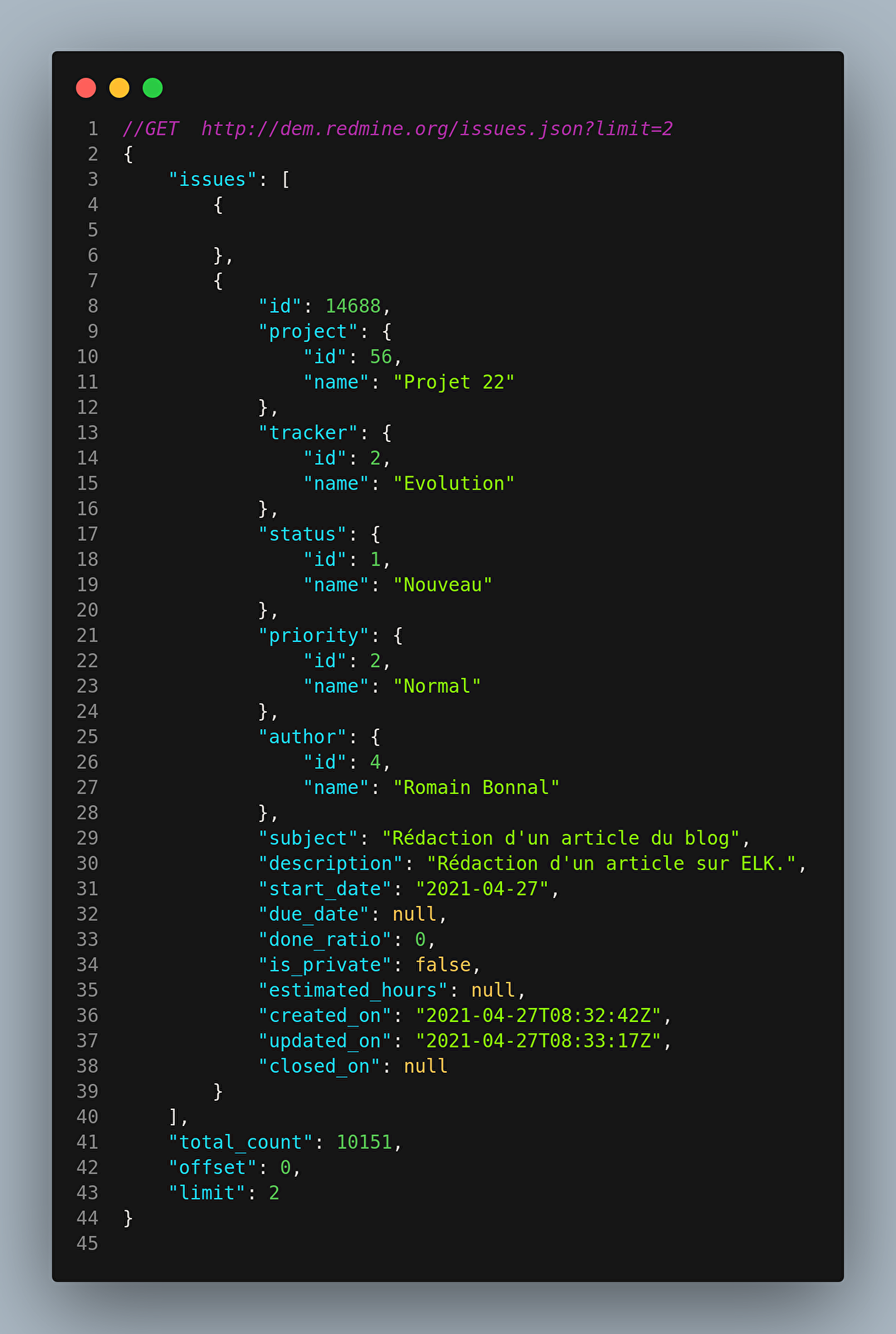
Dans notre prototype, nous avons décidé d’explorer les données associées aux demandes. Voici un exemple de données exposées par la route suivante
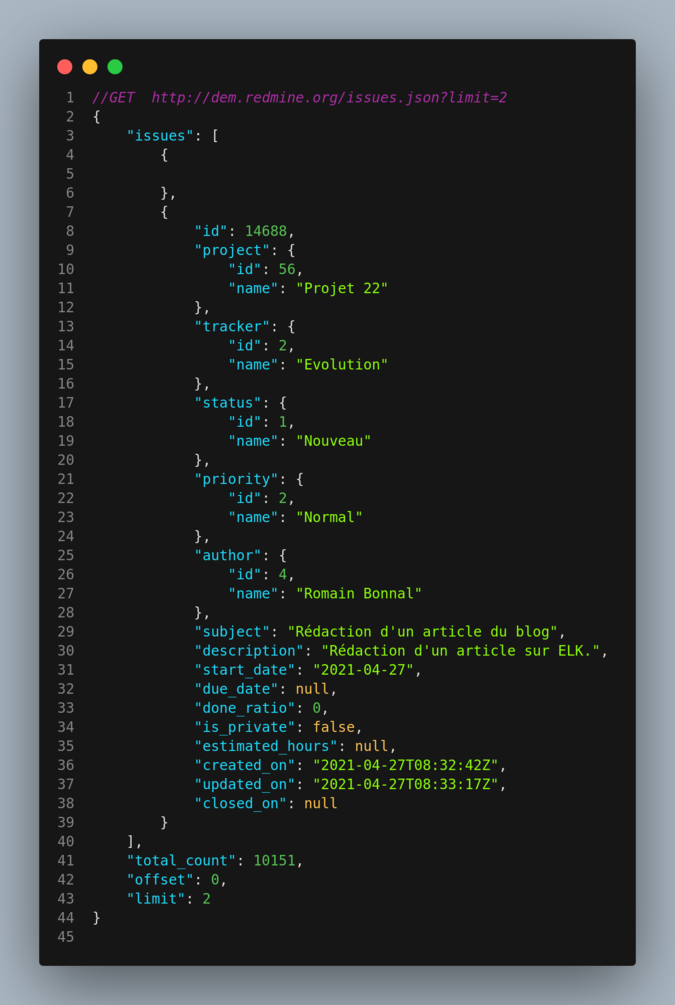
Elasticsearch met à disposition plusieurs API REST permettant la manipulation des données.
https://www.elastic.co/guide/en/elasticsearch/reference/current/docs.html
L'API “bulk” permet d'indexer un lot de données par un seul appel d'API. Cette méthode permet d’augmenter considérablement la vitesse d'indexation.
https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-bulk.html
Nous devons fournir à cette méthode un fichier ndjson contenant les enregistrements à indexer dans Elasticsearch.

Le format attendu est assez simple :
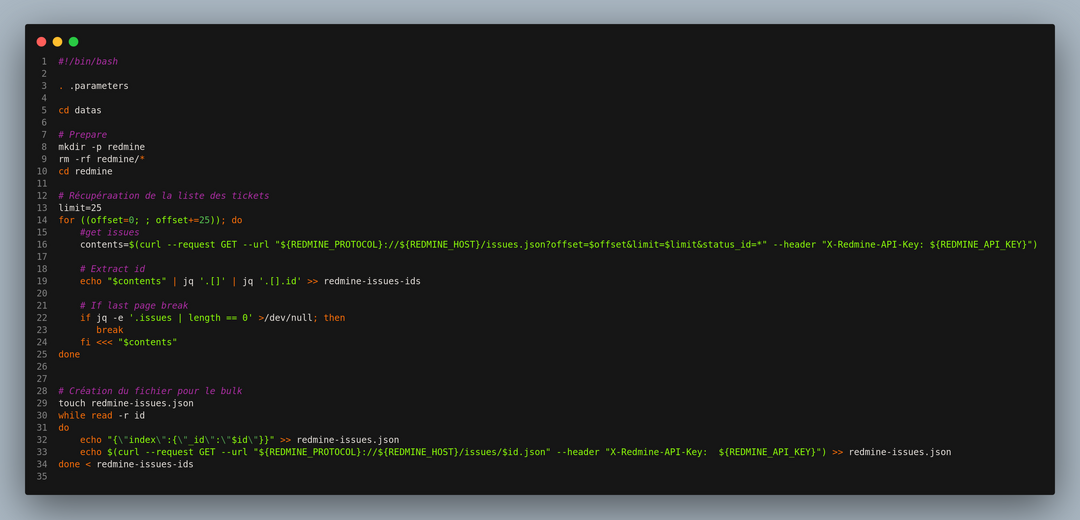
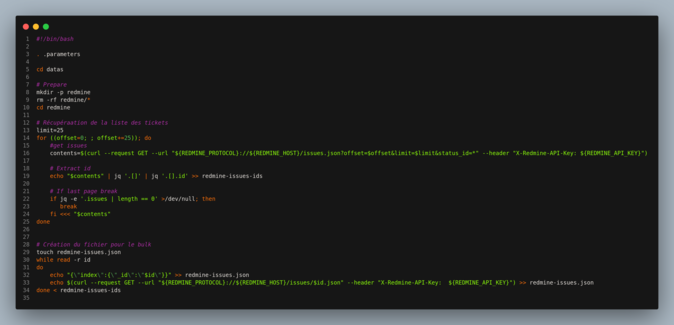
Il est assez facile de construire ce fichier à partir d’un script bash. Quelques itérations sur l’API Rest Redmine ont suffi pour créer ce fichier :
Une fois le fichier généré, il suffit de lancer la commande d'indexation :

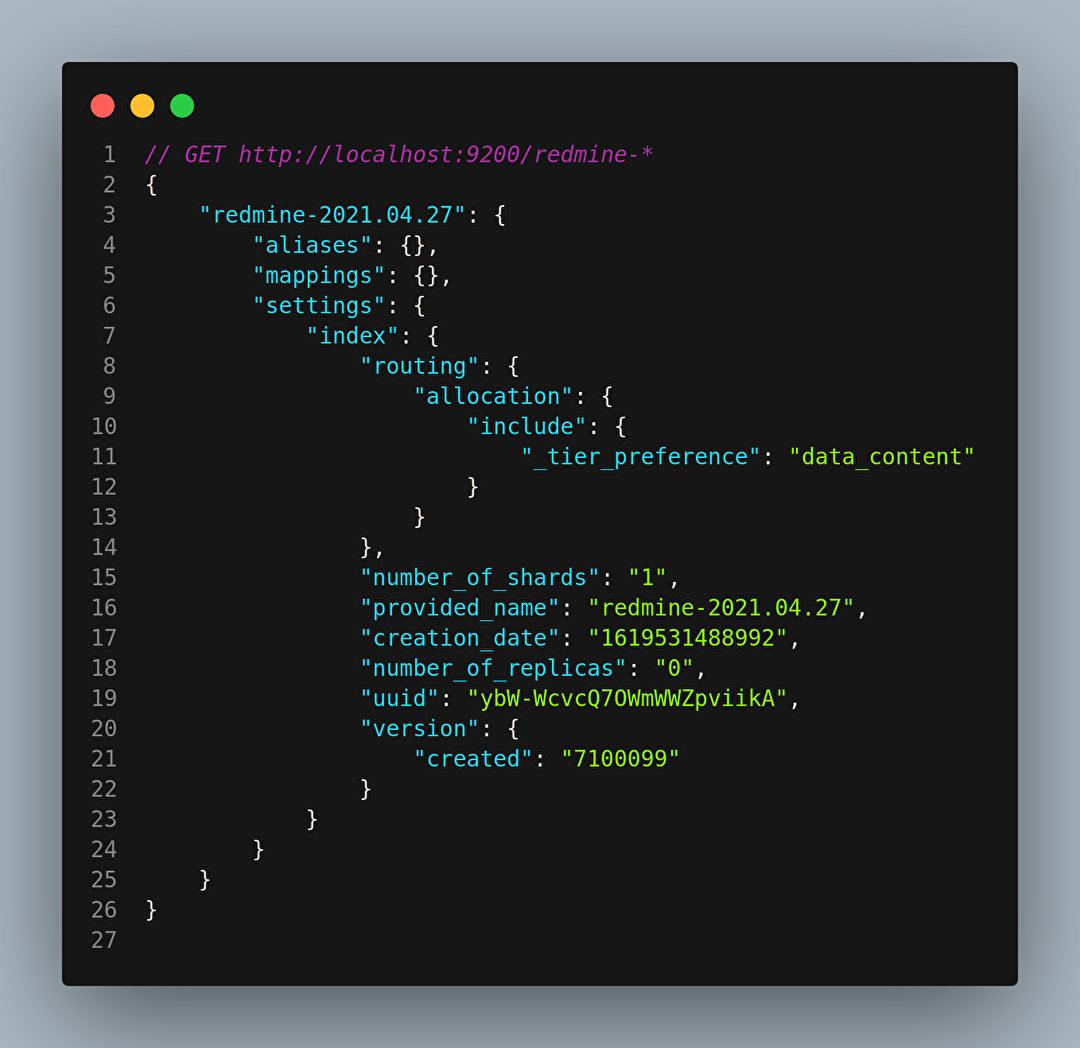
L’indexation d’environ ~15000 enregistrements a duré quelques millisecondes seulement.
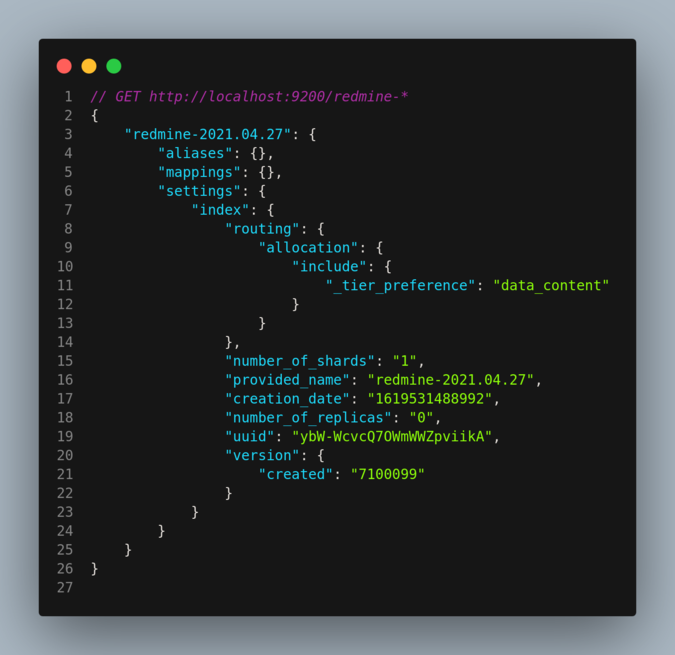
Depuis notre navigateur, nous pouvons vérifier l’indexation d’Elasticsearch. On retrouve bien les enregistrements fraîchement indexés.
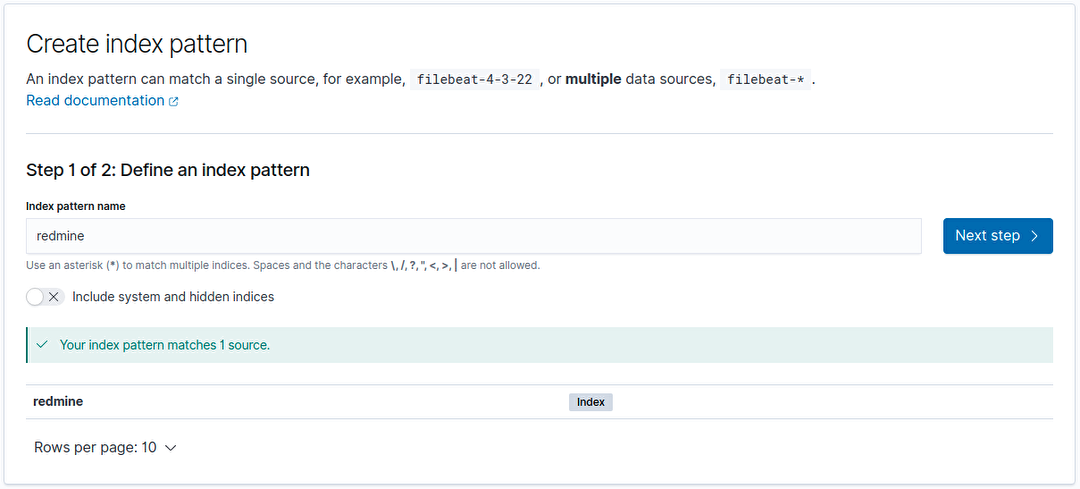
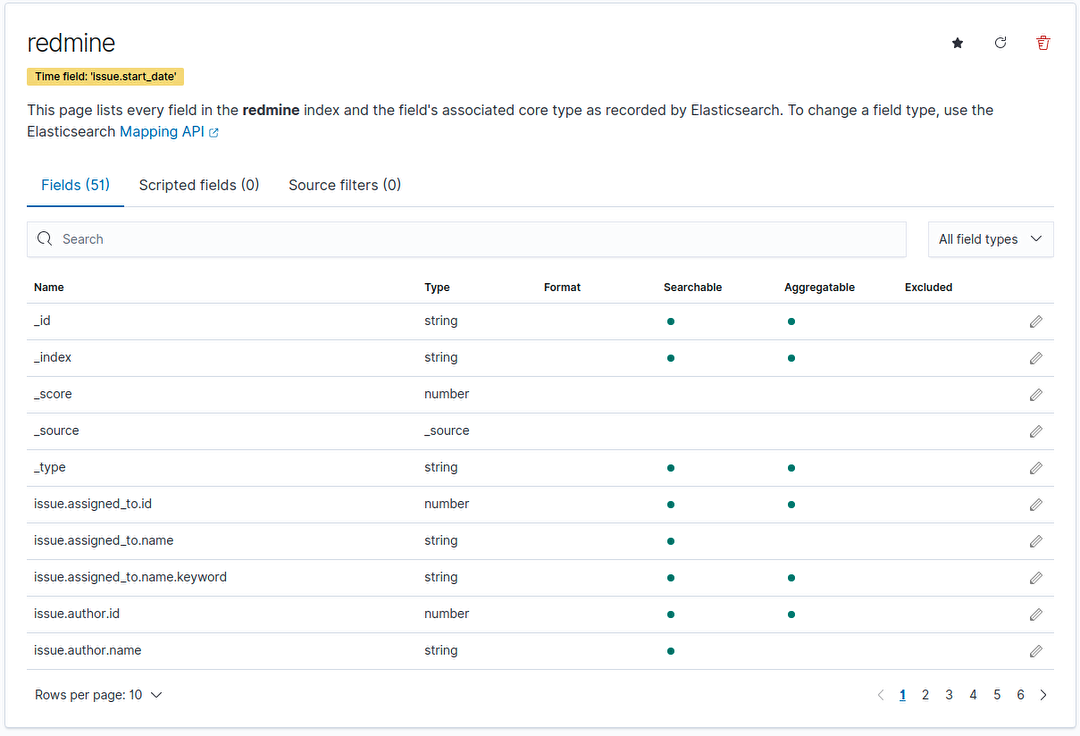
Dernière étape avant de pouvoir explorer les données dans Kibana, la création de l’index pattern.
À cette étape, il est possible de modifier le mapping réalisé automatiquement par elasticsearch lors de l’indexation des données (format des champs, transformation…). Il suffit d’éditer les champs depuis l’interface suivante.
Cette étape peut également être réalisée en amont en définissant un template de mapping a l’aide de logstah (https://www.elastic.co/fr/blog/logstash_lesson_elasticsearch_mapping).
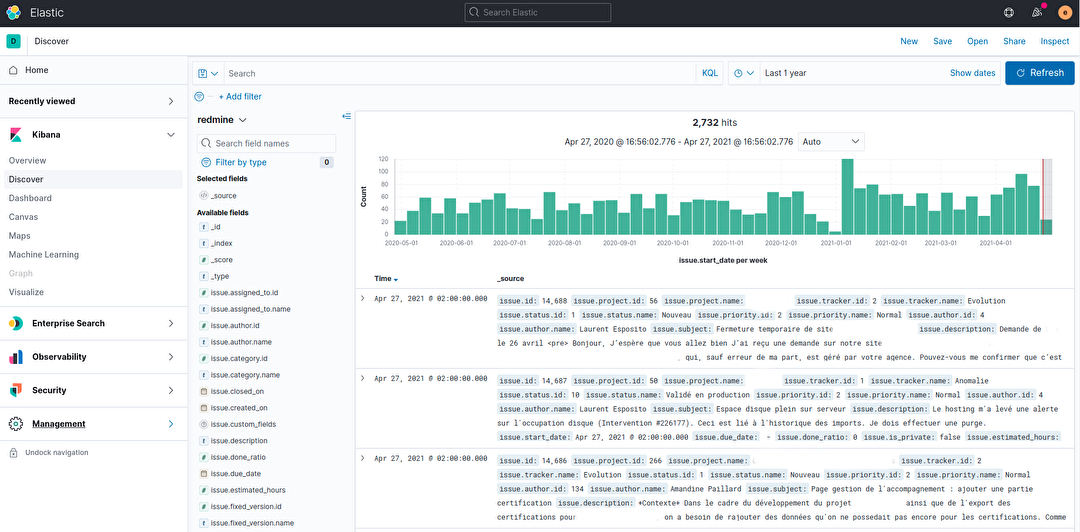
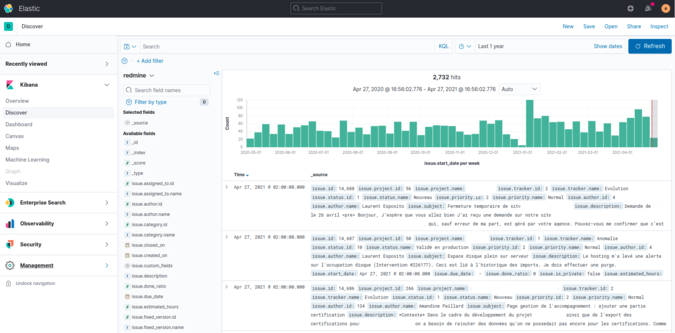
Le module “Découverte” de Kibana nous offre la possibilité d'explorer facilement nos données.
Les experts pourront lancer des requêtes DSL (Domain Specific Language) sur les données.
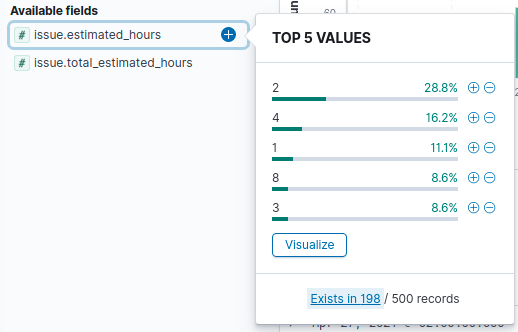
Nous pouvons également cliquer sur les champs pour visualiser les 5 valeurs les plus utilisées pour le champ en question.
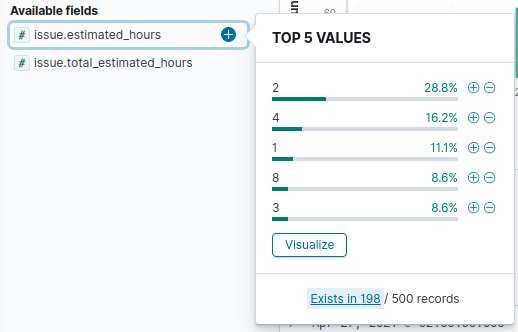
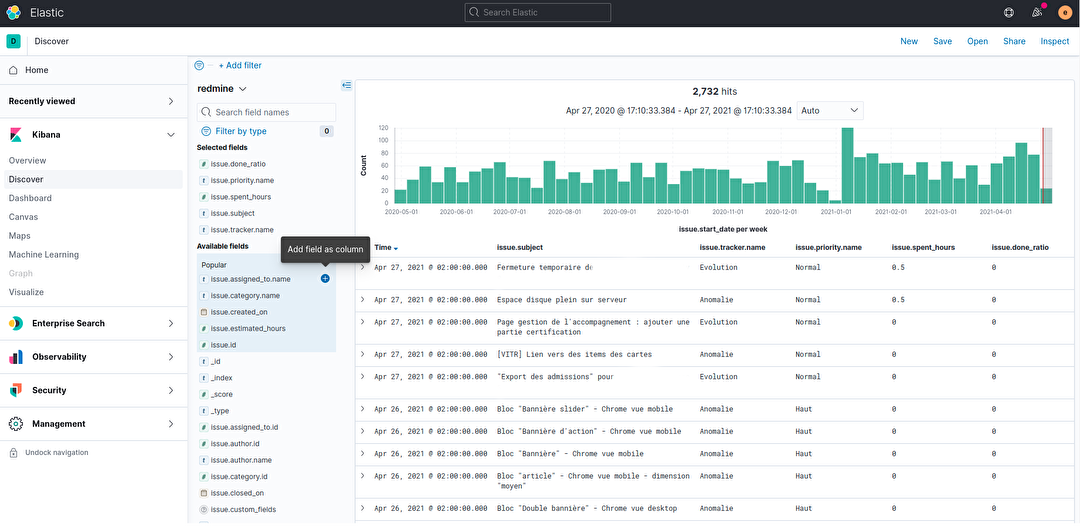
Enfin, nous pouvons construire une vue tabulaire en sélectionnant les champs qui nous intéressent.
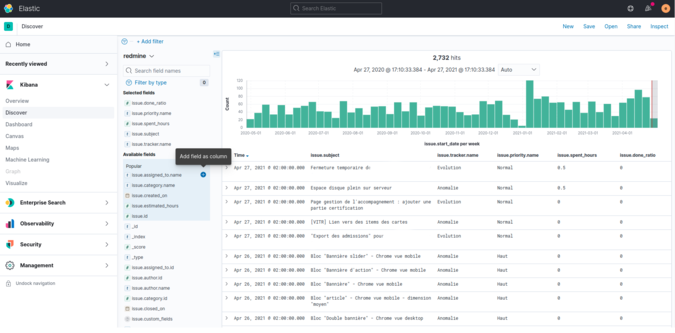
Ce premier module d’exploration est très intéressant. Il nous permet d’affiner la compréhension des données disponibles. Nous pouvons distinguer facilement les dimensions et mesures.
Après une phase d’exploration libre. Nous pouvons nous lancer dans la réalisation de visualisation des données. Pour faire simple, une visualisation correspond à un graphique. Ces visualisations sont autonomes, elles nous permettront par la suite de construire notre tableau de bord.
La première étape consiste à choisir un type de visualisation dans la palette proposée par la plateforme. Cette palette est très complète, on y retrouve des visualisations classiques (tableau, histogramme, camembert, nuage de point, courbe de tendance…) et avancées (carte, carte de chaleur, nuage de mots…).
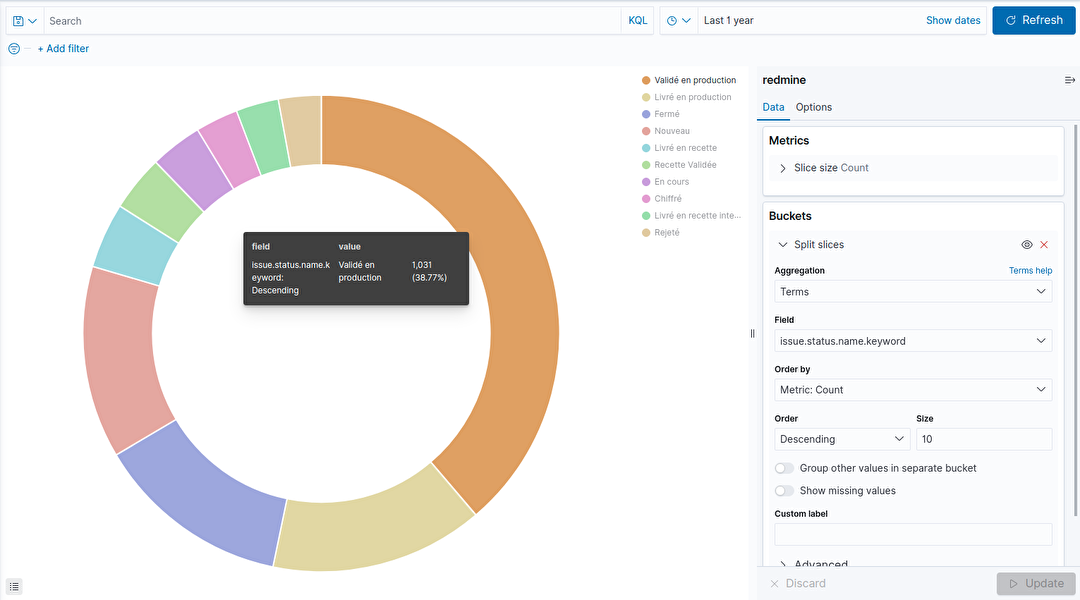
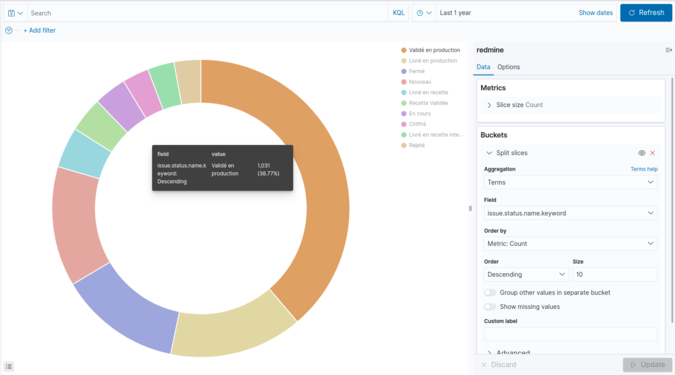
Une fois la visualisation sélectionnée il suffit de définir les mesures et dimensions de notre analyse. Dans l’exemple ci-dessous, nous avons choisi de représenter le temps passé par projet. En quelques clics, nous pouvons visualiser le résultat. Il ne reste plus qu'à enregistrer ce travail.
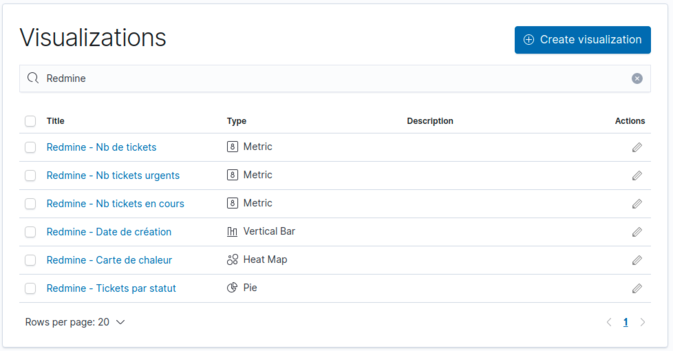
À tout moment, nous pouvons consulter ou modifier les visualisations depuis la page d'accueil du module.
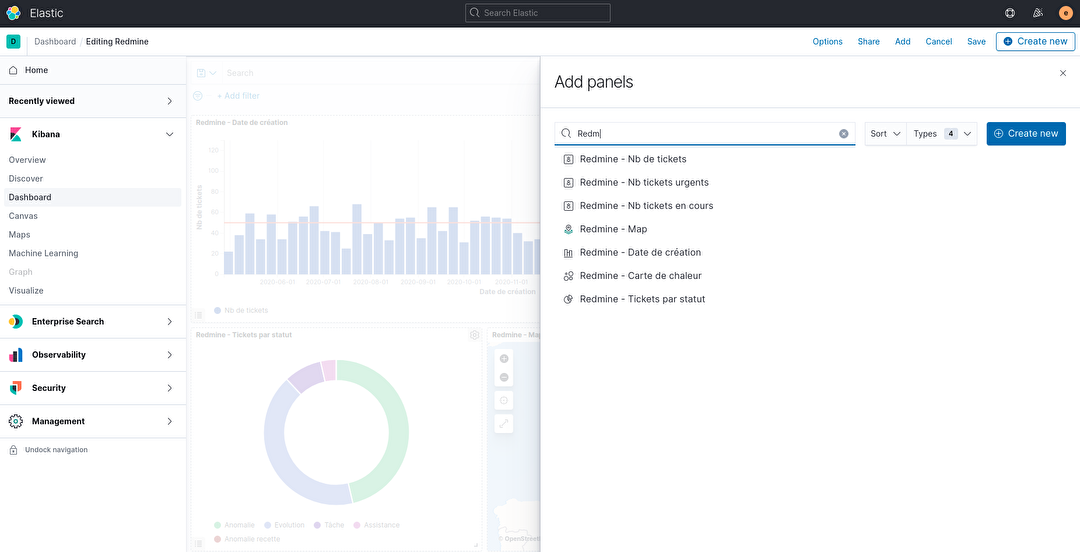
Il est temps à présent de rassembler les différentes visualisations sous forme de tableau de bord. Encore une fois cette opération est très simple. Il suffit d’ajouter les visualisations réalisées à l’étape précédente. Par un simple glisser-déposer, nous pouvons déplacer et organiser notre tableau de bord
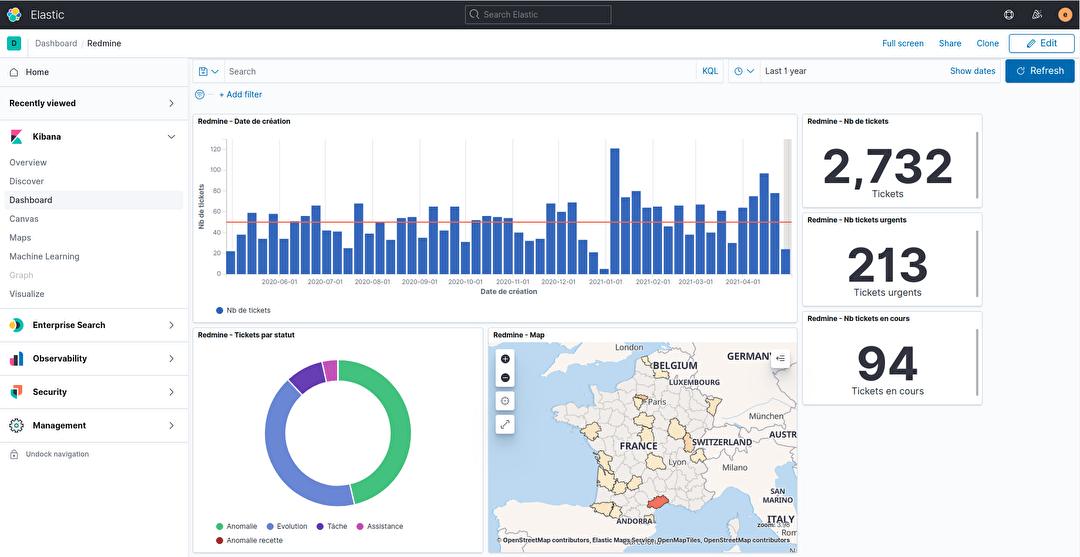
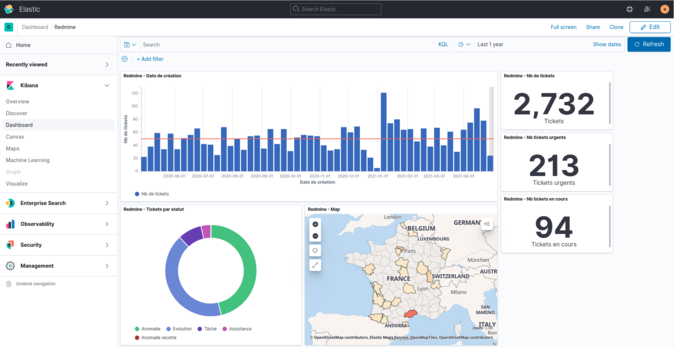
Une fois terminé, il suffit d'enregistrer votre travail. C’est terminé, le tableau de bord est prêt à être utilisé. Nous pouvons ainsi naviguer dans les données :
Dernière fonctionnalité, le partage. Kibana offre la possibilité de diffuser notre tableau de bord sous forme d’iframe. On peut ainsi intégrer notre tableau de bord depuis une autre application métier. Pour des raisons de sécurité, il est néanmoins préférable de mettre en place un serveur proxy pour éviter d’exposer directement Kibana.

Enfin, il faut noter l’absence de module d’export sur la version gratuite. Ce module est disponible uniquement sur la version payante (export pdf et png).
Il est temps de faire un bilan de ce test. La prise en main de la stack elastic est plutôt aisée, même si elle demande quelques compétences techniques. La réalisation de ce prototype a durée 2 jours, installation comprise. Aucune phase d’analyse ou de conception des données n’a été nécessaire. La facilité d’analyse et la puissance de traitement offertes par Elasticsearch accélèrent grandement la mise à disposition d’un premier niveau d'information. Bien sûr, la mise en production de ce travail nécessiterai des travaux supplémentaires :
Cette solution largement utilisée pour le monitoring d’infrastructure et d’application est aussi adaptée à l’exploration et l’analyse de vos données métiers sans cout de licence.


